

AI時代に求められるダイバーシティ&インクルージョンの重要性

昨今、AIチャットボットをはじめとする生成AIの公開により、AIの活用が再び注目を浴びている。Artificial Intelligence(AI)は人工知能を意味し、生成AIは人に代わって大量のデータを学習し、新しい文章やコンテンツを生成する能力を持ったシステムの1つである。生成AIを先行導入しているビジネスの現場では、このテクノロジーが生産性を拡張する技術として、従来人間が行ってきた業務を肩代わりするケースが発生している。同時に、世界各国の企業は、生成AIをどのように効果的かつ倫理的に利活用するか検討を重ねている。一見、英知を結集し答えを導き出してくれる生成AIだが、その活用には盲点があるため、それに関わる私たちにはダイバーシティ&インクルージョン(D&I)の考え方を取り入れ、責任ある行動をすることが求められる。生成AIの登場により、AI活用が多くの企業や人々に身近になった今、改めてその盲点について警鐘を鳴らすとともに、人起点のテクノロジー活用の実現に向けたD&I視点の重要性を論じたい。
本コラムでは、生成系を含むAIの開発・活用において、なぜD&Iの考え方が重要なのか、そして、私たちはどのように多様性・包摂性を担保することができるのか紹介する。
生成AIと機械学習が抱える課題
生成AIは、人間が与える大量のデータ(データセット)や指示(プロンプト)を基に新しい文章やコンテンツを生成する。人間がインプットした訓練データやパターンを学習する能力があるため、データが限られた視点や特定の人口グループに偏っている場合、生成結果にも、社会的な偏見や差別的な要素が反映される可能性がある。学習させる内容は人間が作ったものであるため、人間や組織が持つコンシャス、アンコンシャスを含むバイアスが反映されることは認識しておきたい。
機械学習を基にしたプログラムやAIが持つバイアスについては生成AIが発表される前から懸念されてきた。代表的な事例が米国の「COMPAS(※1)」である。COMPASは、米国の一部の地域で犯罪予測や量刑判断に活用されているプログラムで、犯罪者の犯罪データや個人の特徴を基に再犯リスクを予測しスコア化する。裁判官は、COMPASが算出するスコアを参考にしながら保釈条件や刑期、更生プログラムの参加の判断をすることがある。このプログラムの運用において問題視されたのが、機械学習するデータや予測アルゴリズムのバイアスと公平性である。プログラムは、過去の犯罪データを基に犯罪の再犯リスクを予測するため、過去の犯罪データや判断基準に偏りがある場合、生成結果にもその偏りが反映されてしまう可能性が指摘されてきた。2016年に調査報道をするニュース機関ProPublicaが発表した結果(※2)では、黒人は白人に比べてほぼ2倍の確率で再犯リスクがより高いと判断されたが、実際には同水準では再犯していないことが分かっている。一方、白人については、黒人よりも再犯リスクが低いと出るものの、他の犯罪を犯す可能性が高いことも明らかになった。この事例から明らかになったのは、機械学習において使用される犯罪者の学歴、失業期間、犯罪歴、量刑などのデータと、それを活用・予測するアルゴリズムの設計において、社会的マイノリティである黒人に対して偏った扱いがされていたため、結果として予測結果にも偏りが生じていたことである。
このように、プログラムやAIを開発する側のバイアスが与える影響は大きく、開発者はその責任を認識することが求められる。そして活用する者も、アウトプットにバイアスが含まれているかもしれないことを理解することが大切である。
次章では、D&Iの観点から、生成AI技術を業務活用する各企業が留意すべき点について述べる。
(※1)Correctional Offender Management Profiling for Alternative Sanctions. 代替的制裁のための矯正的犯罪者管理プロファイリング
(※2)ProPublica「Machine Bias」
リスクが高いと判断されたが、再犯はしなかった:白人23.5%/黒人44.9%
リスクは低いとされているが、再犯はあった:白人47.7%/黒人28.0%
開発する側の責任としてのD&I
各企業では、組織特有の大量の情報を学習させ、業務に生成AI技術を活用することが可能になっている。開発者は、以下のようなD&Iの原則(図1)を生成AIの開発に取り入れることで、学習内容に含まれるバイアスを軽減し、公正で包括的な結果の実現につなげることができる。
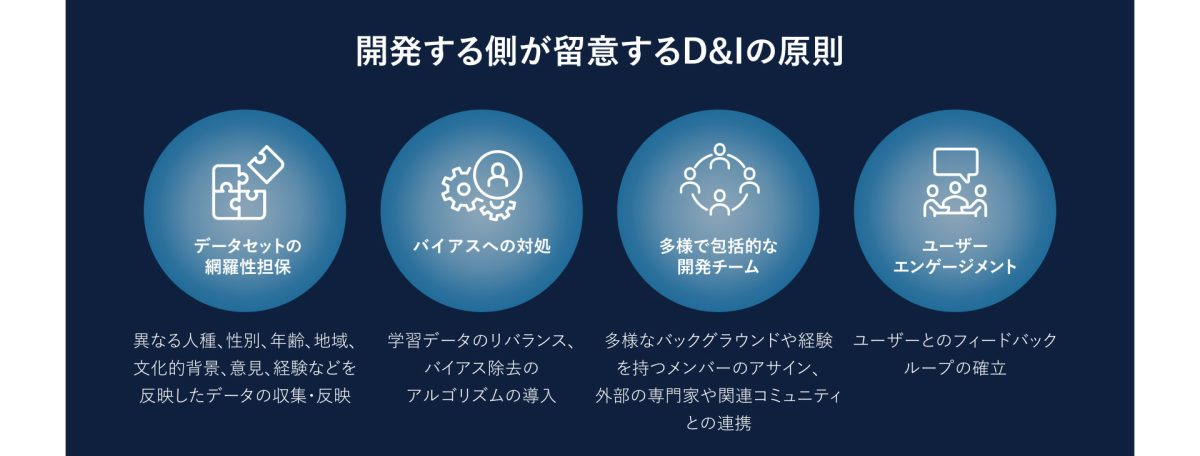
- データセットの多様性の担保―まず開発者は、生成AIモデルの学習に使用されるデータセットにダイバーシティ(多様性)とインクルージョン(包摂性)が担保されていることを確認する必要がある。具体的には、異なる人種、性別、年齢、地域、文化的背景、意見、経験などを網羅するデータを収集し、学習データに取り込むことだ。これによって、生成結果に特定のグループに対する偏りが反映されることを防ぐことができる。
- バイアスへの対処―生成AIの開発者は、学習データ内のバイアスを特定し修正することが求められる。具体的な修正方法としては、特定の属性に関するデータを多め、または少なめに抽出し、生成したデータにバイアスがないように補正することが挙げられる。また、バイアス除去のアルゴリズムを導入し、データセット内の特定の属性に基づいて生成された結果を調整し、より公平な結果が生成されるようにすることも考えられる。
- 多様で包括的な開発チームの組成―生成AIの開発において、データセットのバイアスを特定し対処するためには、多様なバックグラウンドや経験を持つメンバーを揃えることが重要となる。例えば、外部の専門家や関連コミュニティとの連携を通して、特定の領域や文化に精通した人々から積極的にフィードバックやアドバイスを収集することで、バイアスを特定し、モデルの改善につなげることが可能になる。
- ユーザーエンゲージメント―開発者は、定期的に生成AIを活用しているユーザーからのフィードバックの収集を通して、バイアスの有無や公平性を評価し、モデルの改善につなげることができる。ユーザーとのフィードバックループを確立し、モデルの公平性や包摂性を向上させることが望まれる。
活用する側の責任としてのD&I
AI技術を活用する側も、AIの限界を認識し、生成結果にバイアスがないか、つまり公正で包括的であるかどうか、判断することが重要である。AI技術を使う者は、バイアスの軽減や公平性が担保されたAI活用に向けて、以下のような原則(図2)に沿って留意することが求められる。

- バイアスの認知―生成AIを活用するユーザーは、生成された結果にはバイアスが含まれる可能性があることを認識することが重要である。バイアスがあると感じた場合は、プロンプトを繰り返し、生成結果を深掘りしたり、対象範囲を広げたりする工夫が求められる。また、生成結果だけに頼らず、自ら別の情報源を活用することも望まれる。
- ステークホルダーとしての参加―生成AIの結果を利用する側は、ステークホルダーとして開発者に生成結果のバイアスや質についてフィードバックを共有し、バイアスの軽減や情報の公平性、包括性の担保に貢献することができる。また、このステークホルダーエンゲージメント自体が、組織内、社会におけるD&Iを推進することにつながる。
おわりに
生成AIの拡大は、D&Iの考え方を浸透させる契機でもある。開発する側、活用する側がAI技術開発に関わる社会的な責任と倫理観、そしてD&Iの重要性を認識することで、生成AIがより公正で包括的な結果を生成することにつながり、バイアスの軽減と公平性の担保を実現することが可能になる。
Ridgelinezでは、多様なプロフェッショナルが、お客様の変革を成功へ導くために伴走している。私たちは、不確実性が高い世界において持続可能な成長を実現するためには、多様な視点はかけがえのない資産であると考える。今後も、従業員が個々の強みを最大限に発揮できる企業文化を育てることで、より強く、よりレジリエントな組織づくりを実現し、お客様の変革を加速させることを目指したい。





 共鳴する社会展
共鳴する社会展